Check out my Google Scholar profile.
Creating a common language between functionally analogous assistive devices (Ongoing)
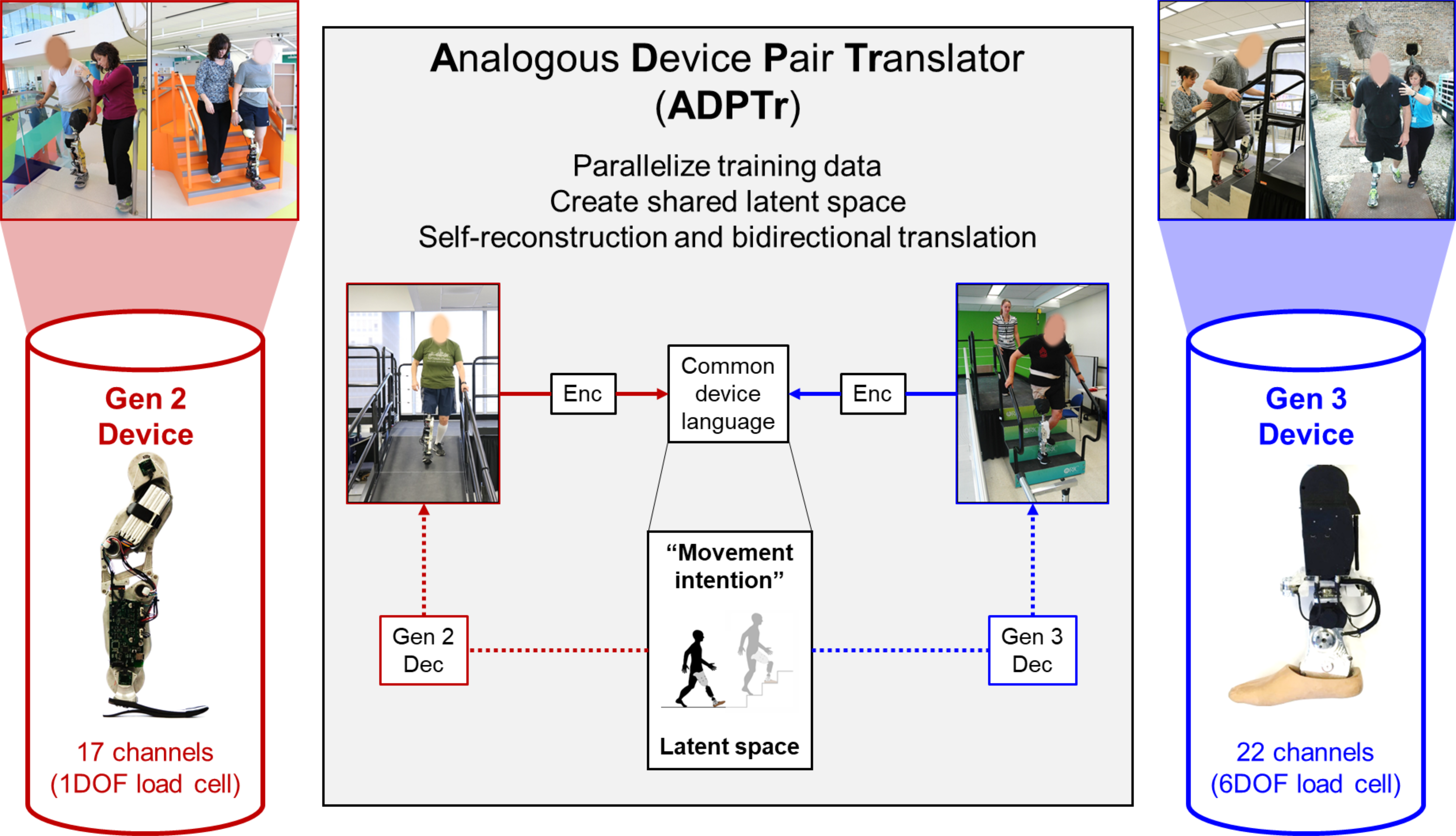
Motivation:
In recent years, rapid development in the field of wearable robotics has led to a proliferation of assistive devices. The perpetual introduction of devices with newer sensors and actuators or improved capabilities is accompanied by the need to develop intuitive, safe, and reliable strategies by which they can be controlled. As a strategy for controlling powered leg prostheses, intent recognition uses movement-related signals detected prior to movement completion to predict the upcoming locomotor activity on a step-by-step basis (e.g. at heel contact and toe off). Usually, labeled examples of each activity are collected as training data for a pattern classification algorithm. However, changes to the configuration of the device will affect performance when using a previously trained classifier. For instance, the type, number, and location of device-embedded sensors may change as the user’s preferences and needs change. But there are currently no methods for recycling the previously collected training data to make it compatible for a different but functionally analogous device configuration. In a worst case scenario, a very experienced user of one device would have to recollect all his or her training data for a different configuration.
Approach:
The key idea is to build a common latent space between the two device domains and to learn a common language by reconstructing sensor signals in both domains according to two principles: (i) the model should be able to reconstruct sensor data for a given device from a noisy version of it (as in standard denoising auto-encoders) and (ii) the model should be able to reconstruct sensor data given a noisy “back-translation” of itself from the other domain. Using adversarial regularization, we constrain the latent representations from both domains to have the same distribution by using a discriminator trained to identify the domain of a given latent code. This process is repeated iteratively, leading to improvements in the translation model.
Deep generative models with data augmentation to synthesize powered leg prosthesis sensor data
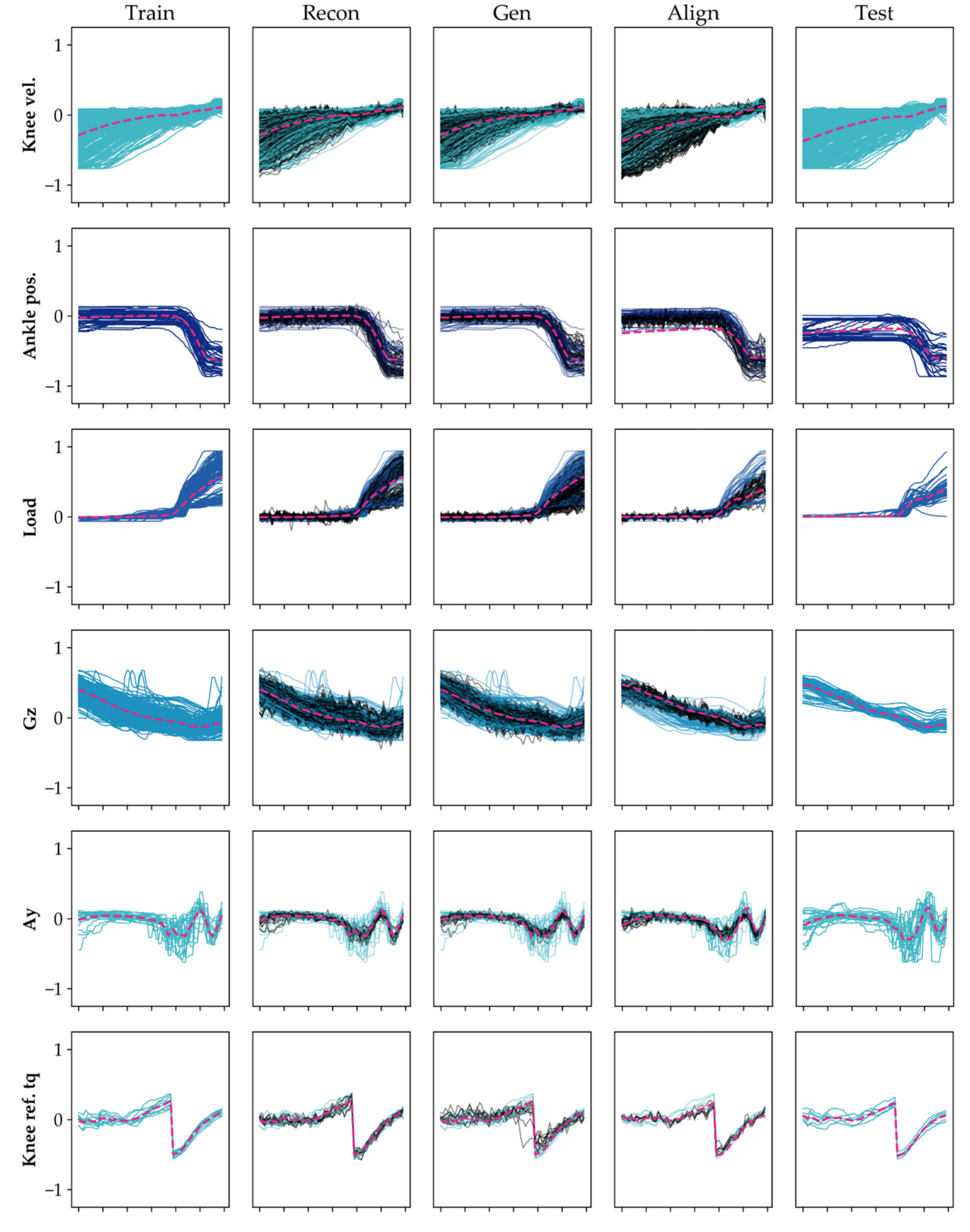
Motivation:
Movement-related signals detected prior to movement completion can be used to train a pattern classification algorithm to predict the upcoming locomotor activity in order to control a powered leg prosthesis (i.e. intent recognition). Intent recognition has already enabled amputees to transition intuitively and seamlessly between different pre-programmed activity modes (e.g. level ground, stairs, ramps); however, collecting labeled training data from an impaired population is tedious. Yet, the collected training data still may not generalize well to new patterns at prediction time for both personal predictive and population pooled models due to factors such as differences in device configuration (alignment, socket fit), user characteristics (shoe height, body measurements, muscle strength), or environment. Therefore, new techniques to improve generalizability to these different test conditions are necessary to minimize the training burden and improve the long-term clinical viability of intent recognition. Our objective was to learn more robust representations of movement intention which could be used to generate realistic prosthesis sensor data reflecting variability across days and users.
Approach:
We selected a data-driven approach using a deep generative model (i.e. semi-supervised denoising adversarial autoencoder) to learn the structure of the variability in the training data aggreggated from four users across different sessions. First, we perform global data augmentation using scaled and shifted copies and additive zero-centered Gaussian noise in the time-domain in order to amplify our empirical training data from tens and hundreds to tens of thousands of examples. Next, we train our models to simultaneously predict the activity labels and generate realistic synthetic data. Lastly, we demonstrate the practical benefit of this approach by evaluating the accuracy of our models when training on fewer real training data (but supplemented with synthetic data) and testing on real data collected from another session in a more ecological environment.
Open access human movement data for improving lower-limb wearable robotics
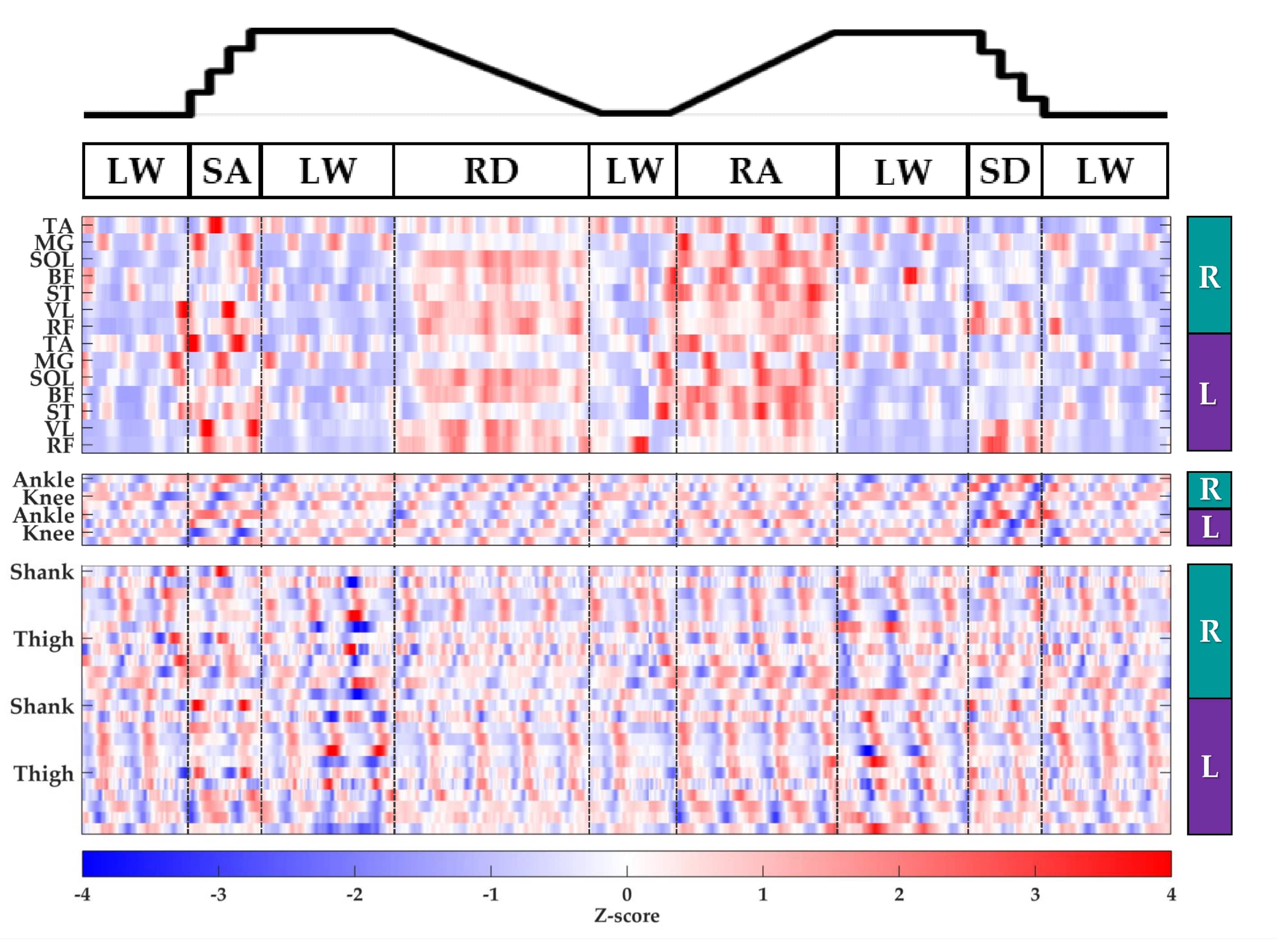
Motivation:
Benchmark datasets containing high-resolution, device-agnostic neuromechanical signals from unimpaired individuals are critical to helping the wearable robotics community objectively evaluate device performance for a variety of walking-related activities. In addition, rich labeled training data from wearable sensors is valuable for developing activity prediction algorithms. Our contribution, the ENcyclopedia of Able-Bodied Lower-Limb Locomotor Signals (ENABL3S), represents a “best case scenario” (i.e. the device is fully transparent and does not impede movement) for activity prediction and is intended to fill a gap in the field by making this type of data publicly available.
Approach:
We used wearable sensors to collect bilateral myoelectric and kinematic signals (52 channels, 1 kHz) from the lower extremities of ten healthy human subjects as they spontaneously transitioned between locomotor activities including level ground walking and ascending/descending stairs and ramps. The experimenter labeled the ground truth with a key fob. We used a temporal raster plot to highlight different patterns in the neuromechanical signals corresponding to different locomotor activities. The unstructured data were cleaned, organized, validated against results aggregated from previously published biomechanics studies, and hosted on Figshare.
| Code | Data Repository | Paper |
Bilateral neuromechanical sensor fusion for intent recognition
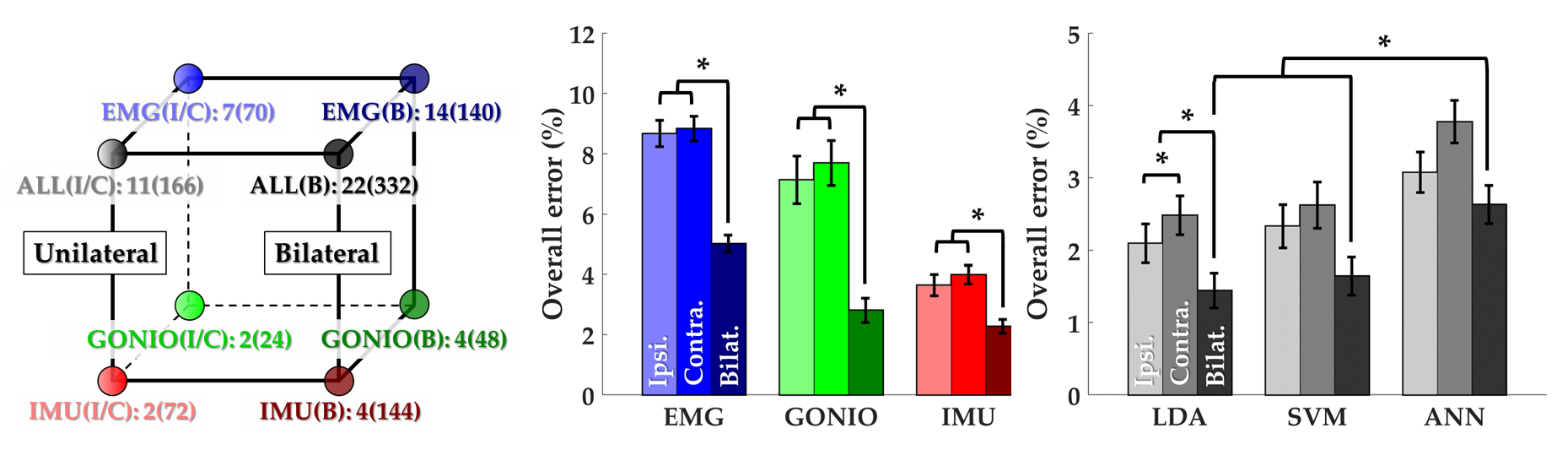
Motivation:
Walking requires interlimb coordination because the leading and trailing legs have distinct biomechanical functions, especially for amputee subjects who already exhibit exaggerated gait asymmetries. However, state of the art intent recognition algorithms have not been systematically applied to bilateral control signals. We tested the hypothesis that including information from both legs would improve accuracy over a controller using unilateral information alone and assessed the practical tradeoffs of performing sensor fusion across legs and modalities.
Approach:
We used the ENABL3S dataset to systematically compare the effect of sensor fusion across legs (unilateral, contralateral, or bilateral) and modalities (myoelectric, kinematic, inertial, or all) on offline prediction accuracy. We segmented windows before critical gait events, extracted heuristic features, and used PCA for dimensionality reduction. We used k-fold cross-validation to compare different sensor configurations and investigated the effect of data dimensionality on the accuracy of three classifiers (linear discriminant, SVM, and neural network). We performed sequential forward sensor selection to determine the number and type of contralateral sensors needed to signficantly improve accuracy compared to a strictly unilateral setup. Lastly, we collected data from one amputee subject wearing an IMU sensor on his non-prosthesis side as a proof-of-concept for the generalizability and benefit of using bilateral control information in an impaired population.
| Code | Paper |
Bilateral gait segmentation using a single sensor
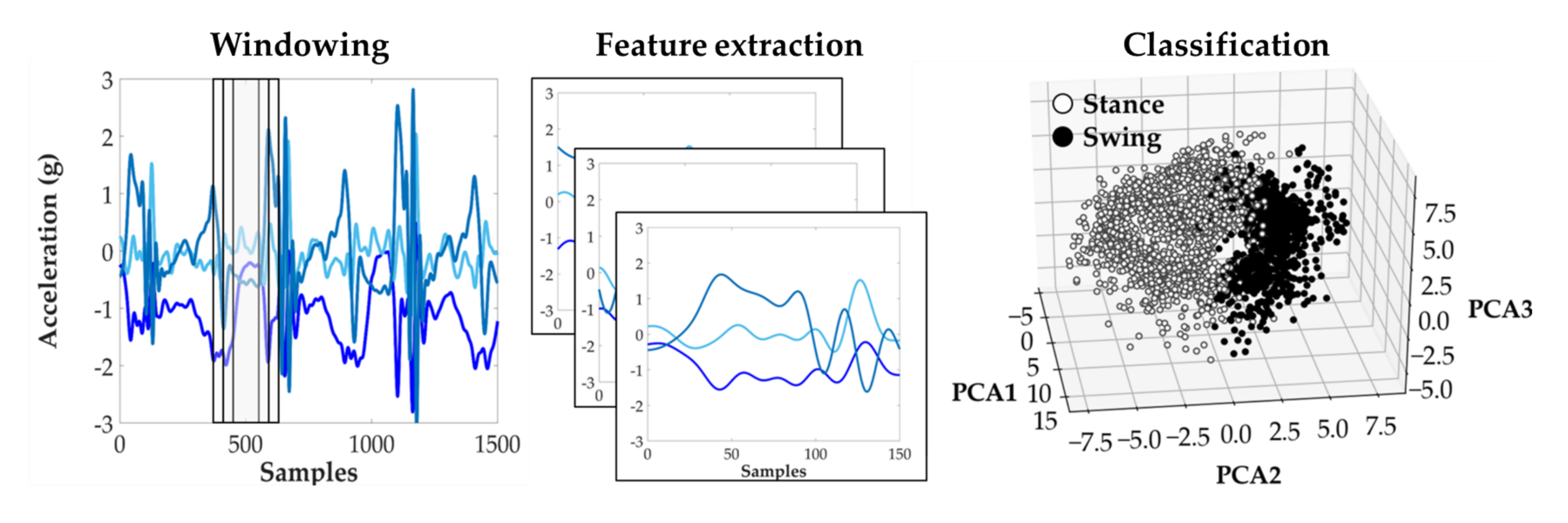
Motivation:
Most wearable lower-limb assistive devices use finite-state machine controllers to segment gait into distinct phases with different biomchanical functions (i.e. control laws). Therefore, the ability to estimate the gait phase (e.g. stance, swing) of one or both legs in an accurate and timely manner greatly affects device safety, function, and efficiency. Specifically, robust detction of double support phase (both feet on the ground) can both help prevent the device from becoming compliant before weight transfer and synchronize power delivery. Existing techniques for bilateral gait segmentation can be cumbersome because they require sensorizing each limb. Therefore, we set out to develop a novel method for bilateral gait segmentation by applying sensor fusion to sensor data from a single thigh-mounted IMU and depth sensor.
Approach:
We developed separate processing pipelines for the IMU and depth sensor data in order to make independent offline predictions of phase (stance or swing) for each leg. For the IMU data, we extracted heuristic features from overlapping sliding windows, performed dimensionality reduction (PCA), and used linear discriminant and SVM binary classifiers to estimate stance and swing phase probabiltiies for each leg. For the depth data, we extracted two novel features (ground and contralateral shank angle) and developed a template matching algorithm to estimate the probability of each phase. Predictions were fused using a weighted average. Our promising initial findings suggest that a creative unilateral sensor fusion strategy can perform as well as a more traditional bilateral sensor configuration.
| Code | Paper | Presentation |